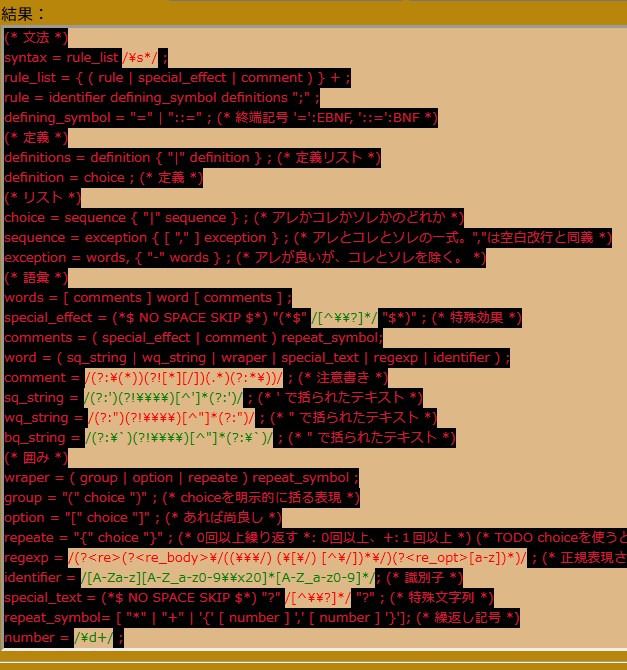
/**
* 色名
*/
const colors = ['black', 'silver', 'gray', 'white', 'maroon', 'red', 'purple', 'fuchsia', 'green', 'lime', 'olive', 'yellow', 'navy', 'blue', 'teal', 'aqua', 'aliceblue', 'antiquewhite', 'aqua', 'aquamarine', 'azure', 'beige', 'bisque', 'black', 'blanchedalmond', 'blue', 'blueviolet', 'brown', 'burlywood', 'cadetblue', 'chartreuse', 'chocolate', 'coral', 'cornflowerblue', 'cornsilk', 'crimson', 'cyan', 'darkblue', 'darkcyan', 'darkgoldenrod', 'darkgray', 'darkgreen', 'darkgrey', 'darkkhaki', 'darkmagenta', 'darkolivegreen', 'darkorange', 'darkorchid', 'darkred', 'darksalmon', 'darkseagreen', 'darkslateblue', 'darkslategray', 'darkslategrey', 'darkturquoise', 'darkviolet', 'deeppink', 'deepskyblue', 'dimgray', 'dimgrey', 'dodgerblue', 'firebrick', 'floralwhite', 'forestgreen', 'fuchsia', 'gainsboro', 'ghostwhite', 'gold', 'goldenrod', 'gray', 'green', 'greenyellow', 'grey', 'honeydew', 'hotpink', 'indianred', 'indigo', 'ivory', 'khaki', 'lavender', 'lavenderblush', 'lawngreen', 'lemonchiffon', 'lightblue', 'lightcoral', 'lightcyan', 'lightgoldenrodyellow', 'lightgray', 'lightgreen', 'lightgrey', 'lightpink', 'lightsalmon', 'lightseagreen', 'lightskyblue', 'lightslategray', 'lightslategrey', 'lightsteelblue', 'lightyellow', 'lime', 'limegreen', 'linen', 'magenta', 'maroon', 'mediumaquamarine', 'mediumblue', 'mediumorchid', 'mediumpurple', 'mediumseagreen', 'mediumslateblue', 'mediumspringgreen', 'mediumturquoise', 'mediumvioletred', 'midnightblue', 'mintcream', 'mistyrose', 'moccasin', 'navajowhite', 'navy', 'oldlace', 'olive', 'olivedrab', 'orange', 'orangered', 'orchid', 'palegoldenrod', 'palegreen', 'paleturquoise', 'palevioletred', 'papayawhip', 'peachpuff', 'peru', 'pink', 'plum', 'powderblue', 'purple', 'rebeccapurple', 'red', 'rosybrown', 'royalblue', 'saddlebrown', 'salmon', 'sandybrown', 'seagreen', 'seashell', 'sienna', 'silver', 'skyblue', 'slateblue', 'slategray', 'slategrey', 'snow', 'springgreen', 'steelblue', 'tan', 'teal', 'thistle', 'tomato', 'transparent', 'turquoise', 'violet', 'wheat', 'white', 'whitesmoke', 'yellow', 'yellowgreen',];
/**
* textColorReplacer内で使用する初期色
*/
const defaultColor = new DefaultColor();
/**
* テキストに色を付ける正規表現のリプレサー
* replace関数のリプレサーのパラメータは以下の通り
* @param {string} match 一致した部分文字列
* @param {string} rs1 1番目のキャプチャグループの結果
* @param {string} rs2 2番目のキャプチャグループの結果
* ・・・
* @param {string} rsN N番目のキャプチャグループの結果
* @param {integer} index 分析中の文字列の開始位置
* @param {string} string 分析中の文字列全体
* @param {object} groups キャプチャグループ全体の抽出結果 {blue: undefined, red= 'false' }
* @returns 置換テキスト
*/
const textColorReplacer = (...args) => {
const match = args.shift(); // argsの先頭から取出す => 一致した部分文字列
const groups = args.pop(); // argsの末尾から取出す => キャプチャグループ全体の抽出結果
const string = args.pop(); // argsの末尾から取出す => 分析中の文字列全体
const index = args.pop(); // argsの末尾から取出す => 分析中の文字列の開始位置
// 残りのパラメータは、各キャプチャグループの結果(正規表現での記載順)
const capGrpResList = args; // キャプチャグループの結果(配列)
/**
* グループ名からテキストを色付け
* @param {string} groupName
* @param {string} match
* @returns 色付けしたテキスト
*/
const colorGroupText = (groupName, match) => {
// グループ名を分割
const re = groupName.split('_');
let element_color = [], not_element_color = [], italic = undefined, underline = undefined, strikethrough = undefined, bold = undefined;
// reを分析
groupName = '';
re.forEach((elm) => {
if (elm === '') { // '' is undefined.
element_color.push(undefined);
} else if (isHex(elm)) { // hex is color code.
element_color.push(`#${elm}`);
} else if (colors.some(col => (col === elm))) {
element_color.push(elm);
if (element_color.length > 2) { element_color.shift(); /* 先頭を削除 */ }
} else {
switch (elm) {
case 'italic': italic = true; break;
case 'underline': underline = true; break;
case 'strikethrough': strikethrough = true; break;
case 'bold': bold = true; break;
default:
not_element_color.push(elm);
break;
}
}
});
// 色情報抜きのグループ名からクラス名を作る
const className = (not_element_color.length > 0) ? (not_element_color.join('_')) : element_color[0];
// 設定内容からfcol,bcolを決定
const fcol = (element_color.length > 0) ? (element_color[0] ? element_color[0] : defaultColor.get(match)) : defaultColor.get(match);
const bcol = (element_color.length > 1) ? (element_color[1]) : 'burlywood';
// fcol, bcol, italicからstyle属性を決定
const style = `${(fcol) ? `color:${fcol}; ` : ''}${(bcol) ? `background-color:${bcol};` : ''}${(italic) ? "font-style:italic;" : ''}`;
// pri, pro
let pri = '', pro = '';
// styleが有効ならspan化
pri = `<span${(className) ? ` class="${className}"` : ''}${(style) ? ` style ="${style}"` : ''}>`; pro = '</span>';
// 修飾名の場合、pri, proに修飾内容を追記
if (underline) { pri += `<u>`; pro = '</u>' + pro; }
if (strikethrough) { pri += `<s>`; pro = '</s>' + pro; }
if (bold) { pri += `<b>`; pro = '</b>' + pro; };
//
return `${pri}${htmlEscape(match)}${pro}`;
};
// 内容が格納されているグループのみテキスト化
const result = Object.keys(groups).reduce((o, groupName) => {
if (groups[groupName]) { o += colorGroupText(groupName, groups[groupName]) }
return o;
}, '');
return result;
}; // end of textColorReplacer.
/**
* テキストに色を付ける
* @param {any} text テキスト(ハズ
* @param {RegExp} regExp 色付け正規表現 ※未指定時は適当な正規表現を割り当てる
* @return {string} 色付け後テキスト
*/
const textColor = (text, re = /(?<blue>true)|(?<red>false)|(?<green>\d+)/gi) => {
text = `${text}`; // 一応テキスト化しておく
let preTag = '', proTag = '';
// 置換してみる
const result = text.replace(re, textColorReplacer);
return result;
}; // end of textColor.