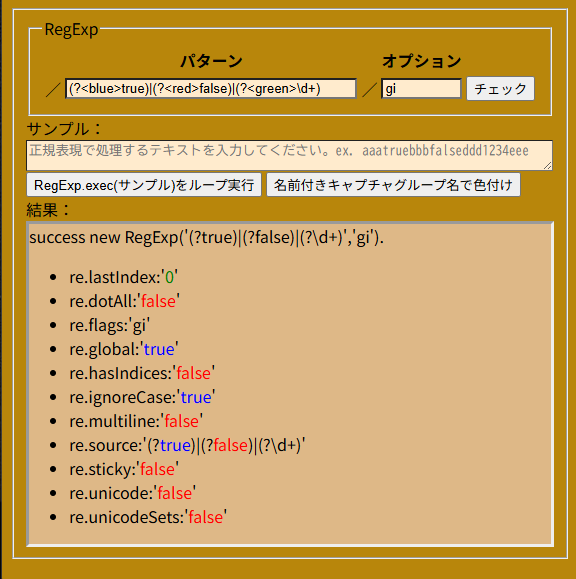
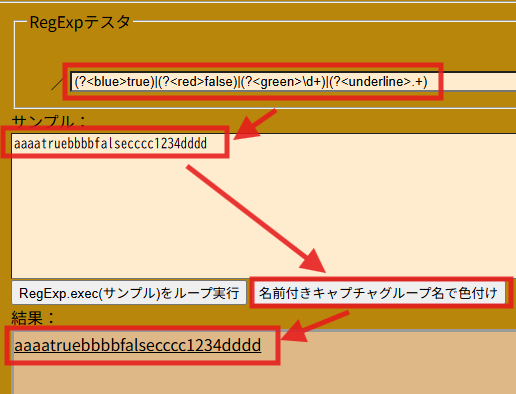
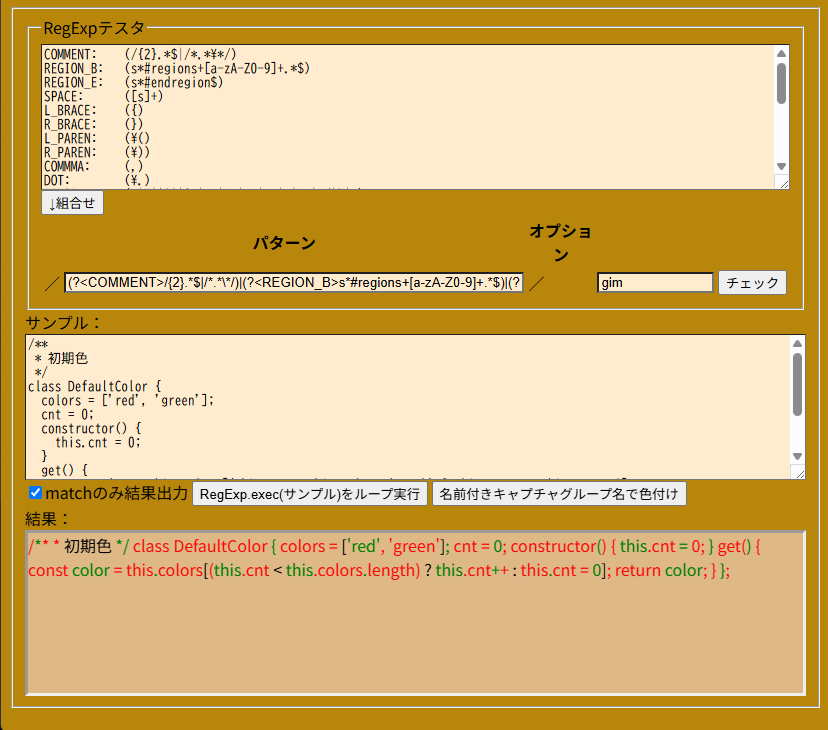
SpreadSheetでちょっと拡張したEBNFをベースに計算式等を評価させていたけど、
やはり顔文字にしか見えない正規表現とかメンドクサイ(ちょっと変えると拗ねるので)
特にリテラルの記述が面倒で、BNFっぽく
wq string = (*$ NO SPACE SKIP $*) '"', /(?!\\\\)[^"]*/, '"' ;と苦し紛れだったので
wq string = '"' ・・・ '"' ;BNFにこんな感じで書けると、とても楽そう
内部では
const encloseParser = parser.enclose(parser.token('"'), parser.search('"', true));な感じで[ ” ]と[ ” ]で囲まれた文字リテラルを判定できる(ハズ
encloseはこんな感じで、囲まれたテキストを返す
/**
* 記号で囲むリテラル用のパーサを作成する
* @param {Function} leftParser 左囲みtoken
* @param {Function} rightParser 右囲みsearch
* @return {Function} 生成した連結パーサ
*/
enclose(leftParser, rightParser) {
const methodName = 'enclose';
const encloseParser = () => {
const bkPosition = this.position;
const leftParsed = leftParser();
if (!leftParsed.status) {
return new ParserResult(false, null, bkPosition);
}
const rightParsed = rightParser();
if (!rightParsed.status) {
return new ParserResult(false, null, bkPosition);
}
const encloseText = this.target.substring(leftParsed.position, rightParsed.position - rightParsed.result.length);
return new ParserResult(true, encloseText, this.position);
};
encloseParser.type = methodName;
return this.parserWraper(encloseParser;
};見慣れないsearchパーサは、
/**
* 一致するパターンを検索するパーサを生成する
* yオプションを付けないregExpバージョン
* @param {string} text 検索パターン
* @param {boolean} fEscape エスケープ処理
* @return {Function} 生成したパーサ
*/
search(text, fEscape = undefined) {
const methodName = 'token';
const len = text.length;
// エスケープ処理の指定が無い場合
if (fEscape === undefined) { fEscape = this.fEscape; }
const rePat = `(${(fEscape) ? '?<!\\\\)(' : ''}${regExpEscape(text)})`;
const re = new RegExp(rePat, '');
const searchParser = this.regexp(re, 'gm'); // yオプションを付けないregExpバージョン
searchParser.type = methodName;
return searchParser; // regexpParserでparserWraper済
};ほぼyオプションの無いパターンを探しにいってしまうregexp処理になっているので
regexpもちょっと変更
/**
* 正規表現パーサを作成する
* @param {RegExp} re 正規表現
* @param {*} options オプション ※未設定の場合は、正規表現のオプション+gmyオプション
* @return {Function} 生成したパーサ
*/
regexp(re, options) { // g:lastIndexから開始、m:複数行、y:lastIndexでのみ判定
const methodName = 'regexp';
const source = re.source;
if (options === undefined) {
options = (re.hasIndices ? 'd' : '')
+ (re.global ? 'g' : 'g') /* lastIndex利用が必須なため、常時gオプションを付加 */
+ (re.ignoreCase ? 'i' : '')
+ (re.multiline ? 'm' : 'm') /* 改行を跨いで処理すたい場合もあるので、常時mオプションを付加 */
+ (re.dotAll ? 's' : '')
+ (re.unicode ? 'u' : '')
+ (re.unicodeSets ? 'v' : '')
+ (re.sticky ? 'y' : 'y') /* regexpは index=0 のみ判定する方が都合が良いので、常時yオプションを付加 */
;
}
try {
re = new RegExp(source, options);
} catch (ex) {
const msg = `${rgis.className}.${methodName}: new RegExp fail, ex:'${ex}'`;
console.error(msg);
throw new Error(msg);
}
/**
* 生成した正規表現パーサ
* @return {ParserResult} パースした結果
*/
const regexpParser = () => {/* regexp */
re.lastIndex = this.position; // 再利用時のため
const result = re.exec(this.target); // とりあえず正規表現で実行
if (result) {
// 読取りに成功した場合
const foundText = result[0];
// ログに追記
this.mapLog.addSuccessToken(foundText);
// 読取り位置を更新
this.position = result.index + foundText.length;
return new ParserResult(true, foundText, this.position);
} else {
// 読取りに失敗した場合
// ログに追記
this.mapLog.addFailToken(source);
return new ParserResult(false, null, this.position);
}
};
regexpParser.type = methodName;
return this.parserWraper(regexpParser, true, false);
};普通は、こんなBNF表記を挟まずに直接パーサコンビネーションを作りはじめるハズだが・・・
最終的には「湯出たてのスパゲッティー」にソースや香辛料をかけて、食べやすく「フォークで絡めて」食べる訳で、文法をちょっとイジるにも脳内のイメージを頼りにパーサコンビネーションをイジるから
バグると「脳内のイメージが間違ってる場合」と「勘違いしてコードしている場合」を切り分けるのが非常に難しい。
あと、パーサはまとめてクラス化してるので各パーサにテキストや読込位置をパラメータで渡すのを止めてみたから、SpreadSheetに組み込むのは完成した後になる。
今は、
{
title: "sequenceメソッド:正常パターン4",
testCase: () => {
const parser = new CoreParser('abc=defghijklmnopqrstuvwxyz')
const sequenceParser1 = parser.sequence([parser.token('abc'), parser.token('='), parser.token('def')]);
const rc = [];
rc.push(sequenceParser1());
return rc;
},
expectedResult: [
{ status: true, result: ['abc', '=', 'def'], position: 7, },
],
},test[4:sequenceメソッド:正常パターン4] success. => [ 0:{ "status": true, result:[ "0": "abc", "1": "=", "2": "def", ], "position": 7, }, ], 単体テストを消化中。
これがいっぱい修正漏れが出るんだなぁ(笑
後になって、実行するパーサや結果がどのパーサが作ったのか判るようにtypeを追加してみたり
※用途未定
テスト結果の判定経過を出力させたり
[ 0:{ "status": true, result:[ "0": "abc", "1": "=", "2": "def", ], "position": 7, }, ], とか、出来てしまえば不要に思えるけど、バグったら必須な機能をパーサ本体の外においても
パーサ本体が600行にもなってしまう。
ps.2025/5/12
「?」最小マッチングで
/'.*?'/
👉 / ' .* ? ' / ※見やすいように空白を挟んでみたと’…..’をお手軽にマッチングできるけど、エスケープ(\’)が混ざるとどうして良いのか判らなかったけど、
'(.*?\\')*.*?'
👉 ' (.* ? \\' )* .* ? ' ※見やすいように空白を挟んでみたの様に「エスケープ(\’)を0回以上繰り返す」を挟めばOKだった。
気づけば簡単すぎ。(大笑
だがどうやってうまく処理できてるのか?
.* ? \’ から .* ? ‘ に遷移するには
先回りして「\\’」や「’」の位置を把握し存在を確認し、「\\’」や「’」の直後に切り詰めてマッチングし、存在しなければ左部のマッチングをしないのかな?
※\\’が存在しない長いテキストを渡すと重そうだけど
正規表現も
/ .* /
こんなザックリとした表現は意味は読み取れるけど使い物にならないが
👉 / .* ? /
でちょっとは使えるので、
正規表現内で/が出現する状況を挟み込んで
👉 / ((.* ? \/)|(.* ? [/)|(.* ?(/)|(.* ?{/))* .* ? / ※ / に 4連の (.* ? を仕掛けるぞ(的な
で良いのかもしれない。
※とても十分な検証をする気にはならないがががで済むのかな?
顔文字表現より見やすい気がするけど、ジェットストリームっぽくドムだから処理が重いかも。