以前作ったJSのUTF-16をSJISに変換するサンプルが時代の波にモマれ動かなくなってたので作り直し。
それにつけても非推奨が増える一方な感じがするJS。
同様に正規表現のデバッガも動かなくなっていた。(【javascript】 RegExp 正規表現のデバッガ)
でも正規表現で名前付きキャプショングループを使える様になってきたみたいだから良しとしよう。
※2016年の記事(9年も前か!)だし、単に使いこなせなかったかもしれないけどね。
今回は名前付きキャプショングループのおかげで内容をとても単純になった。
正規表現の/…/の中のパターンとオプションを手入力して【チェック】ボタンを押すと
new RegExp({正規表現パターン}, {オプション})が動き、RegExpオブジェクトのプロパティを画面下の結果欄に表示する。
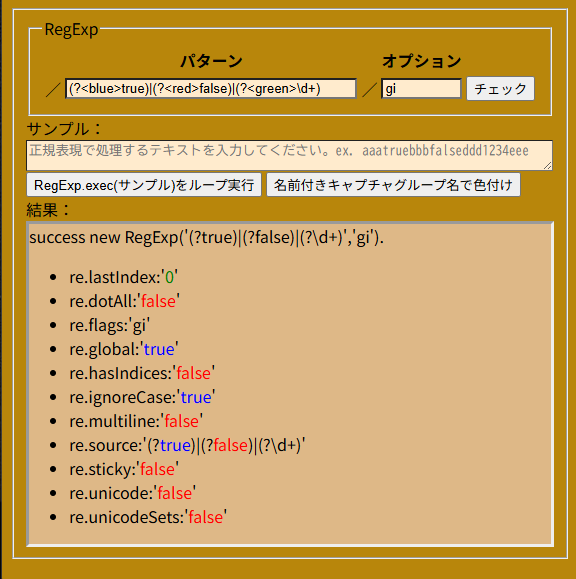
だけのハズだったが、
実際 サンプルをRegExe.execメソッドに与えてみないと
文法上正しいだけの正規表現になってしまうので、
【RegExp.exec(サンプル)をループ実行】ボタン
whie(true) {
if({正規表現パターン}.exec({サンプル}) {
#結果に出力を追記
} else {
break;
}
{無限ループチェック}
}を追加した。
空の正規表現パターンを無限ループ内のexecメソッドに与えると空振りし続け
CPUファンが最大回転数になる上にブラウザが「メモリが~メッセージ」を出すので
空回りしない様にしてる。(つもり
名前付きキャプチャグループ名をCSSの色名にすれば、replaceメソッドに正規表現とリプレッサーを組み込めば、簡単にテキストの色付けができる様になってた。(笑
※色指定方法:キャプチャーグループ名_文字色_背景色と(_)で区切る。
前回の苦労は何だったのかな?(只の徒労だな(昔は大変だったよね?(笑って忘れよう
【名前付きキャプチャグループ名で色付け】ボタン
{サンプル} .replace ( /{正規表現パターン}/{オプション} , {名前付きキャプチャグループ名で色付けする処理} ) も追加した。
正規表現パターンを拡張しテキストの文字を全て色付けできたら「完成」なんだろうなぁ~
正規表現パターンが完璧なのにテキスト中に色指定無しがあれば、多分「シンタックスエラー」だから
replaceで「<span style=”color: xxx”>・・・</span>」部分を消去すれば、エラってる箇所を抽出できそうダケど、色指定をdarkgrayに差し替えるか色指定が無い部分に下線属性を付加した方が見つけやすそう。
正規表現の最後に何でもヒットするパターンに下線の名前を付ければ、
(?<blue>true)|(?<red>false)|(?<green>\d+)|(?<underline>.+)
で
aaaatruebbbbfalsecccc1234dddd
を色分けしてみると?予想外の部分に下線が付くと思ったら、全部下線が付いてしまった(合掌
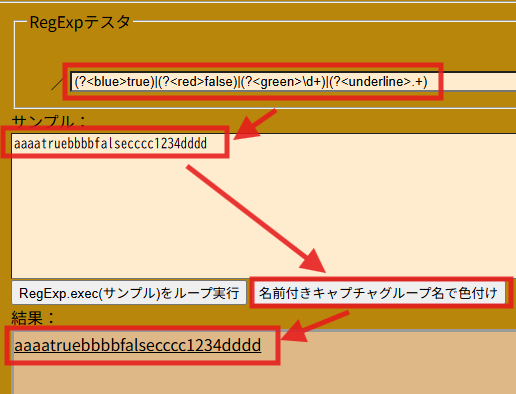
ま、気軽に進めよう(笑
以下、サンプルデータ。
(?<blue>true)|(?<red>false)|(?<green>\d+)giaaaatruebbbbfalsecccc1234dddd最後に画面が寂しいのでtitleとplaceholder属性を追記した。
今はtitle内容を改行して表示させるには\nと書いてもブラウザが”\n”と思ってしまうので、

テキストエディタ上で直にLFコードを入れる(Enterキー押下)しかなけど、気が付いたら\nって書けば改行してくれる様な気がする。

最近のテキストエディタは「Enterキー」入力をCR、LF、CRLFのいづれかに変更する機能を持つものが多いので何とかなるけどね。
ps.2025/4/16
画面はサンプルなデータを初期表示して試しやすく(具体的にはデバッグ)した。コードも少し変えてみた。
結果にオブジェクトの内容を表示する処理を共通化してみた
JSONなオブジェクトでは十分だけど、
for(const propertyName in oobject)
クラスでは静的なプロパティしか見せたくないらしく出てこない。
/**
* JSON.stringifyのreplacer
* @param {*} key
* @param {*} value
*/
const stringifyReplacer = (key, value) => {
if (key !== '' && !value) {
value = 'undefined';
}
return value;
};
/**
* オブジェクトのプロパティを列挙
* @param {object} object オブジェクト
*/
const objectPropertyStringify = (object) => {
let ar = {};
// for(..in object)
for (const id in object) { ar[id] = object[id]; }
// Object.keys(object)
const keys = Object.keys(object);
keys.forEach((id) => { ar[id] = JSON.stringify(object[id], stringifyReplacer, 0); });
// Object.getOwnPropertyNames(object)
const props = Object.getOwnPropertyNames(object);
props.forEach((id) => { ar[id] = JSON.stringify(object[id], stringifyReplacer, 0); });
// Object.getOwnPropertyNames(obj.__proto__)
const prototypeProps = Object.getOwnPropertyNames(object.__proto__);
prototypeProps.forEach((id) => { ar[id] = JSON.stringify(object[id], stringifyReplacer, 0); });
// 纏め
const txts = [];
for (const id in ar) {
// typeof value !== 'function' で メソッドを排除
if (typeof object[id] !== 'function') {
txts.push(`${id}:${textColor(ar[id])}`);
}
}
//
return `<ul><li>${txts.join('</li><li>')}</li></ul>`.replace('<li></li>', '');
};アレレ?配色が効かない!
/**
* JSON.stringifyのreplacer
* @param {*} key
* @param {*} value
*/
const stringifyReplacer = (key, value) => {
if (key !== '' && !value) {
value = 'undefined';
}
return value;
};
/**
* オブジェクトのプロパティを列挙
* @param {object} object オブジェクト
*/
const objectPropertyStringify = (object) => {
let ar = {};
// for(..in object)
for (const id in object) { ar[id] = object[id]; }
// Object.keys(object)
const keys = Object.keys(object);
keys.forEach((id) => { ar[id] = JSON.stringify(object[id], stringifyReplacer, 0); });
// Object.getOwnPropertyNames(object)
const props = Object.getOwnPropertyNames(object);
props.forEach((id) => { ar[id] = JSON.stringify(object[id], stringifyReplacer, 0); });
// Object.getOwnPropertyNames(obj.__proto__)
const prototypeProps = Object.getOwnPropertyNames(object.__proto__);
prototypeProps.forEach((id) => { ar[id] = JSON.stringify(object[id], stringifyReplacer, 0); });
// 纏め
const txts = [];
for (const id in ar) {
// typeof value !== 'function' で メソッドを排除
if (typeof object[id] !== 'function') {
txts.push(`${id}:${textColor(ar[id])}`);
}
}
//
return `<ul><li>${txts.join('</li><li>')}</li></ul>`.replace('<li></li>', '');
};
にしている。
後、文法解析用の字句解析にReExpの(…)|(…)|…|(…)な書き方用【↓組み合わせ】機能も追加。
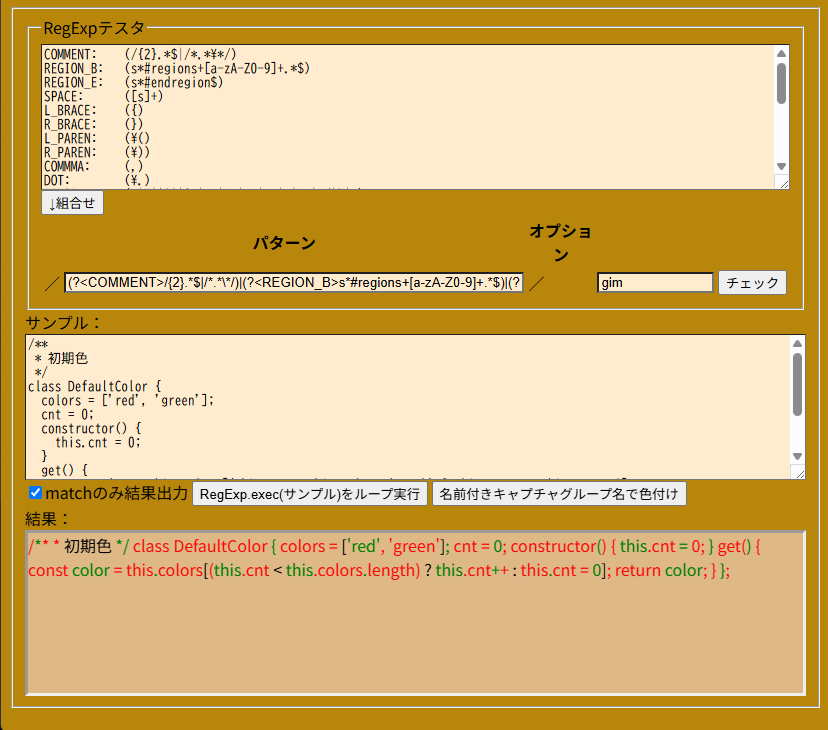
ちゃんと字句解析できてるかと思いきや「初期色」が読み飛ばされていた。
キャプチャー名が名前以外の場合は適当に色を割り当ててます。(今は2色を交互に使ってる。
※2025/4/17 : 配色が赤・緑・赤・赤・緑・赤・赤・緑と変なので修正、空白にも配色してたので修正。読飛ばされた箇所は背景色を黒にしてみた。早速「:」忘れてたのに気が付く。
長いログを見ても判りにくいのでexecを実行させる際に「macthしたテキストのみ」結果に出るチェックボックスを追加してみた。
※2025/4/17 : 名無しキャプチャーグループのみの正規表現でも表示する様に修正
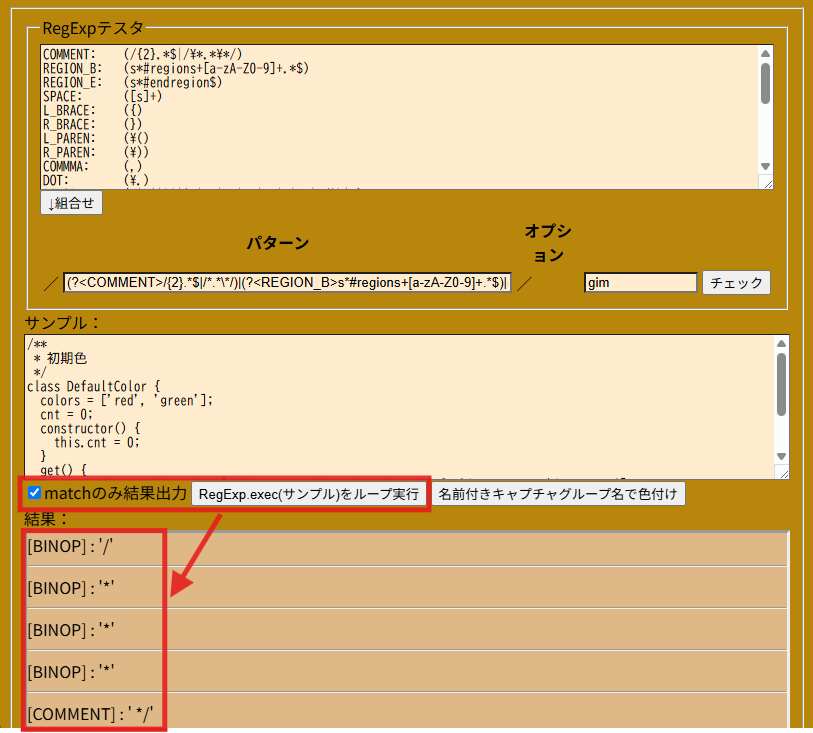
なるほど、BINOP単項演算子に見えたか
完成までの道程はまだ遠い
※適当なソースを貼って遊ぶとオモシロイかもしれないけど、ページを「保存」してローカルで遊びましょう。
/* ・・・ */の複数行コメントの字句解析が思わしくない。
- Windowsから貼ると改行がCRLFになると正規表現のmオプションが暴走しやすい
- 仕方がないからCRLFはLFに置換
- 「/* コメント1 */ コード /* コメント2 */」と複数のコメントがあると
- 「/* コメント1 */ コード /* コメント2 */」と一括りにしてしまう
- 「/* コメント1 / コード / コメント2 /コード / コメント3 /」と複数のコメントがあると
- 「/ コメント1 / コード / コメント2 /コード / コメント3 */」と一括りにしてしまう
- パターンを先読みアサーション((?=…))、([\s\S]*)、後読みアサーション((?<=…))
- 「(?=ここから/*) ([\s\S]*) (?=*/ここまで)」も
- 「ここから/* * */ここまで * ここから/* * */ここまで」と一括りにしてしまう
- 初期表示のサンプルは/* … */は1つだけなので2度コピペすると↑を際限できます
- とりあえず良さげなパターンが見つかった。
- COMMENT: (/{2}.$|\/\*\/?([^/]|[^*]\/|\r|\n)*\*\/)
- \/\*:つまり / *
- [ \ s | \S ]* を使うと 最後に見つけた * / までブチ抜けくので
- \/?([^/]|[^*]\/|\r|\n)* で頑張る
- 先頭の\/?:/*直後に/があった場合のお守り
- ([^/]|[^*]\/|\r|\n)*: */ 以外のパターンのつもり
- ( と ) * で中のパターンを0回以上繰り返し
- [^/] | [^*] \/ | \r | \n
- 非 / or 非 * and / or CR or LF であるから
- 非 / と 非 * and / と改行のパターンを0回以上繰り返すパターンの意味
- ( と ) * で中のパターンを0回以上繰り返し
- \*\/:つまり * /
- CR: ([\r|\n]+)
- 記事にペーストなんか違う?勝手に斜体になってる???
- まさかWordPressの記事入力のエスケープシーケンスまで絡んでくるとは思わなんだ
- COMMENT: (/{2}.$|\/\*\/?([^/]|[^*]\/|\r|\n)*\*\/)
結果に改行がそのまま出力してたので<br/>に変えた。
ついでに空白も や&emsp;に変えたらなぜか色設定が消えた!(あ、タグの中に空白がいっぱい
font-familyの設定もイジることにした見やすくなった。(結果オーライ
ps,2025/4/18
’ ・・・ ’の字句解析が思わしくない。
- \’ ・・・・ ‘ も判定してしまう。
- LITERAL: (‘[^’]*’) では不完全らしいから
- WQLITERAL: (“[^”]*”) や QLITERAL: (‘[^’]*’) もダメだろう。
- LITERAL: (‘[^’]*’) では不完全らしいから
- でも普通はいきなり \’ なんて出てこない
コードの中の正規表現の後がズタズタだった・・・(涙
spreadSheetを作ってた時もBNF記述でハマってた。パーサーコンビネーターで作ってたから厳密な字句解析をすっ飛ばして token === ‘/.*/{flags}’ でいいや的な誤魔化しができた。
正規表現でコードハイライトのラスボスは正規表現
嫌すぎ
ps.2025/4/18:多少改善できたので更新。
TODO:/\\/な正規表現が苦手で、以下ボロボロになる。
text = text
.replaceAll(/\\/g, '\\\\') 👈今この辺で滞っている
.replaceAll(/\"/g, '\\"')
;
copyClipboardText(`new RegExp("${text}", "${flags}");`);
やっと片付いた(かもしれない
COMMENT: (\/{2}.*$|\\/\\*\\/?([^/]|[^*]\\/|\\r|\\n)*\\*\\/)
CR: ([\\r|\\n]+)
SPACE: ([\\s]+)
BQLITERAL: (\`(\\\\\\\\|\\\\\`|[^\`]|\\r|\\n)*\`)
LITERAL: (\'(\\\\\\\\|\\\\\'|[^'])*\')
WQLITERAL: ("(\\\\\\\\|\\\\"|[^"])*")
REGEXP: (\\/(\\\\\\\\|\\\\/|[^\\/])*\\/[a-z]*)
REGION_B: (s*#regions+[a-zA-Z0-9]+.*$)
REGION_E: (s*#endregion$)
L_BRACE: ({)
R_BRACE: (})
L_PAREN: (\\()
R_PAREN: (\\))
L_BRACKET: (\\[)
R_BRACKET: (\\])
COMMMA: (,)
COLON: (:)
DOT: (\\.)
BINOP: (\\|\\||&&|===|!==|!=|==|\\+|<|>|\\?|<=|>=|-|\\*|\\/|%|=|!)
DELIMITER: (;)
NULL: (null)
VALUE_TYPE: (void|integer|bool|string)
SCOPE: (public|private|friend|static)
THIS: (this)
NEW: (new)
BOOL: (true|false)
SYMBOLE: ([_a-zA-Z0-9]+)
NUMBER: ([1-9][0-9]*[.]?[0-9]*)
※オプションは「gim」指定時のみ有効。
から【↓組合せ】ボタンで論理和で結合したパターンを貼り付ける。
このパターンとオプションからVScodeに貼ると、自動的にフォーマッタが働きグチャグチャになるので
"・・・"
とペーストする部分をクリックした後にそ~っとペーストしなければいけない。
※【コピー】ボタンでエスケープ処理済みのテキスト(↓参照)をクリップボードにコピーさせてからファイルにペースト。
const re = new RegExp(
"/(?<COMMENT>\\/{2}.*$|\\/\\*\\/?([^/]|[^*]\\/|\\r|\\n)*\\*\\/)|(?<CR>[\\r|\\n]+)|(?<SPACE>[\\s]+)|(?<BQLITERAL>`(\\\\\\\\|\\\\`|[^`]|\\r|\\n)*`)|(?<LITERAL>'(\\\\\\\\|\\\\'|[^'])*')|(?<WQLITERAL>\"(\\\\\\\\|\\\\\"|[^\"])*\")|(?<REGEXP>\\/(\\\\\\\\|\\\\\\/|[^\\/])*\\/[a-z]*)|(?<REGION_B>s*#regions+[a-zA-Z0-9]+.*$)|(?<REGION_E>s*#endregion$)|(?<L_BRACE>{)|(?<R_BRACE>})|(?<L_PAREN>\\()|(?<R_PAREN>\\))|(?<L_BRACKET>\\[)|(?<R_BRACKET>\\])|(?<COMMMA>,)|(?<COLON>:)|(?<DOT>\\.)|(?<BINOP>\\|\\||&&|===|!==|!=|==|\\+|<|>|\\?|<=|>=|-|\\*|\\/|%|=|!)|(?<DELIMITER>;)|(?<NULL>null)|(?<VALUE_TYPE>void|integer|bool|string)|(?<SCOPE>public|private|friend|static)|(?<THIS>this)|(?<NEW>new)|(?<BOOL>true|false)|(?<SYMBOLE>[_a-zA-Z0-9]+)|(?<NUMBER>[1-9][0-9]*[.]?[0-9]*)",
"gim");
な感じなら、使用しているjavascriptファイルは大体OK(だと思う
リテラル系の「 \ \ \ \ \ \ \ \ 」:「\」8キャラが酷い。
- javascriptファイル上の「 \ \ \ \ \ \ \ \ 」:「\」8キャラ
- をjavascriptエンジンが読み込んで
- 「\\」を「\」に変換するので
- 「 \ \ \ \ 」:「\」4キャラのデータになる
- これを渡されたRegExpクラスも
- 「\\」を「\」に変換するので
- 「 \ \ 」:「\」2キャラのデータになる。
なのでRegExpに「 \ 」を2キャラ渡すために
javascriptのソースコードには「 \ \ \ \ \ \ \ \ 」と8キャラ書くことになる
なんてこったい。(知ってたけど
ついでにココ(段落)に貼るとWordPressのエスケープシーケンスが即反応するので、専用のプラグインに貼る方がいい。
ps.2025/4/19:少し調整
・テキストエリアでタブキーを入力できる様にした
・正規表現のキャプチャーグループ名に文字色と背景色を指定できるようした
COMMENT_RED_000000 な感じに書くと
色付け処理で、
グループ名を(_)で区切って「グループ名_文字色_背景色」な感じで色付けできる。
色番号の「#」はキャプチャーグループ名に使えないので「#」を除いた16進表記のみ書く。
これで、ちょっと「(」が読みにくいので色を変えるとかが簡単になった。
ps.2025/4/23
XMLのツリービュー表示で使う正規表現のデバッグをしていたら
正規表現
(?<attr_name>[-:a-z]+)(?<attr_sep>=)(?<attr_value>"[^"]*")|(?<attr_name>[-:a-z]+)|(?<SP>[\t\s\r\n]+)
サンプル
<style:style style:family="paragraph" style:name="a213">一度のexec実行で複数のグループがヒットする正規表現の場合には・・・
[attr_name, attr_sep, attr_value] : '{attr_nameの抽出結果のみ}'と最初の抽出結果しか表示してないコトに気付いたので
[キャプチャ1名]:'{キャプチャ1抽出結果}'、・・・[キャプチャn名]:'{キャプチャn抽出結果}'の様な感じに変更した。

隣の「色付け」ボタンを押すとキャプチャ対象外の文字は赤で背景色が黒で表示するので、

あ、「<」と「>」を無視してるじゃん!
とか判りやすいと思う。