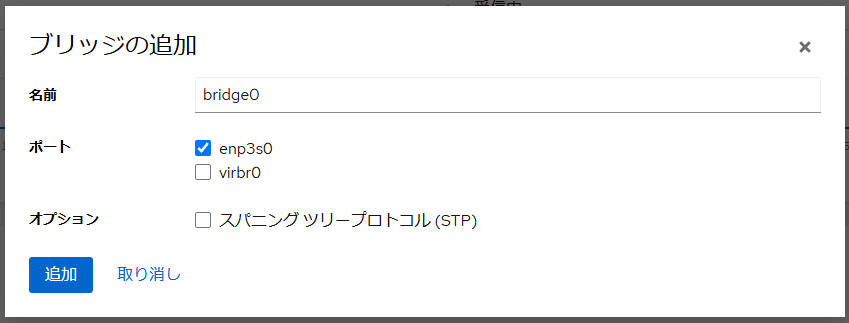
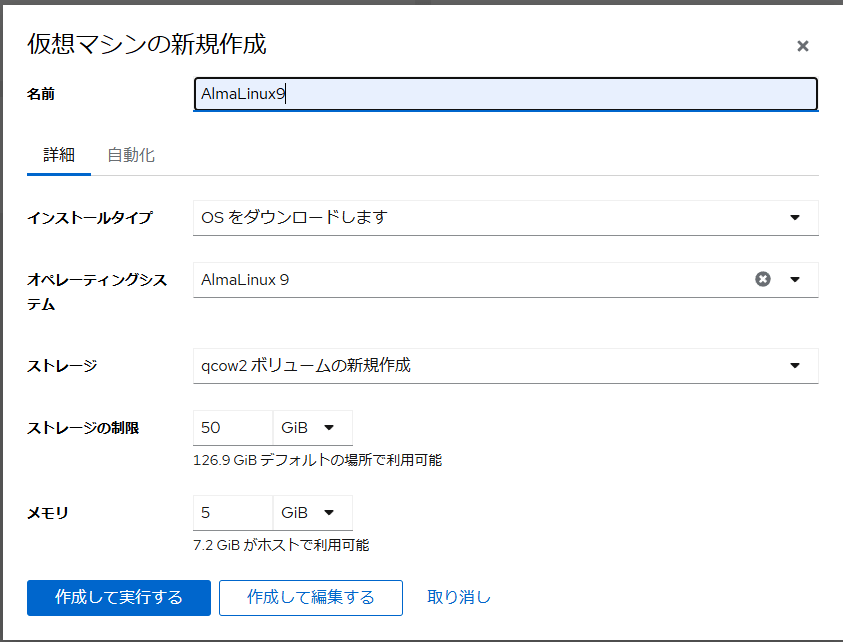
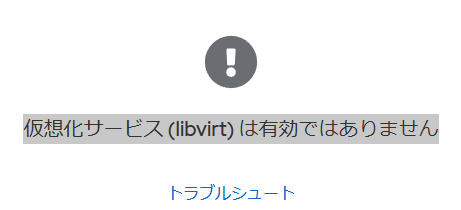
コンテナと云えばDockerなんだろうけどRedhatのコマンドから削除され、代わりにPodmanが入ったらしい。
cockpitのアプリケーションの画面にPodmanがあるので【インストール】ボタンを押してみる。
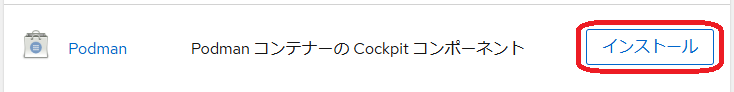
# podman --version
podman version 5.2.2イメージをダウンロードしてみる。
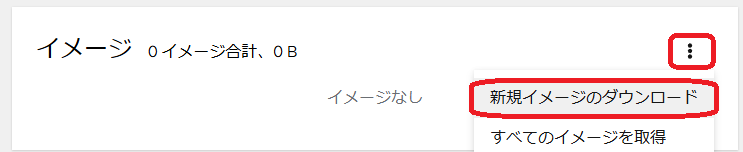
docker.ioからAlmaLinux9のminimalを選んでダウンロードしてみる
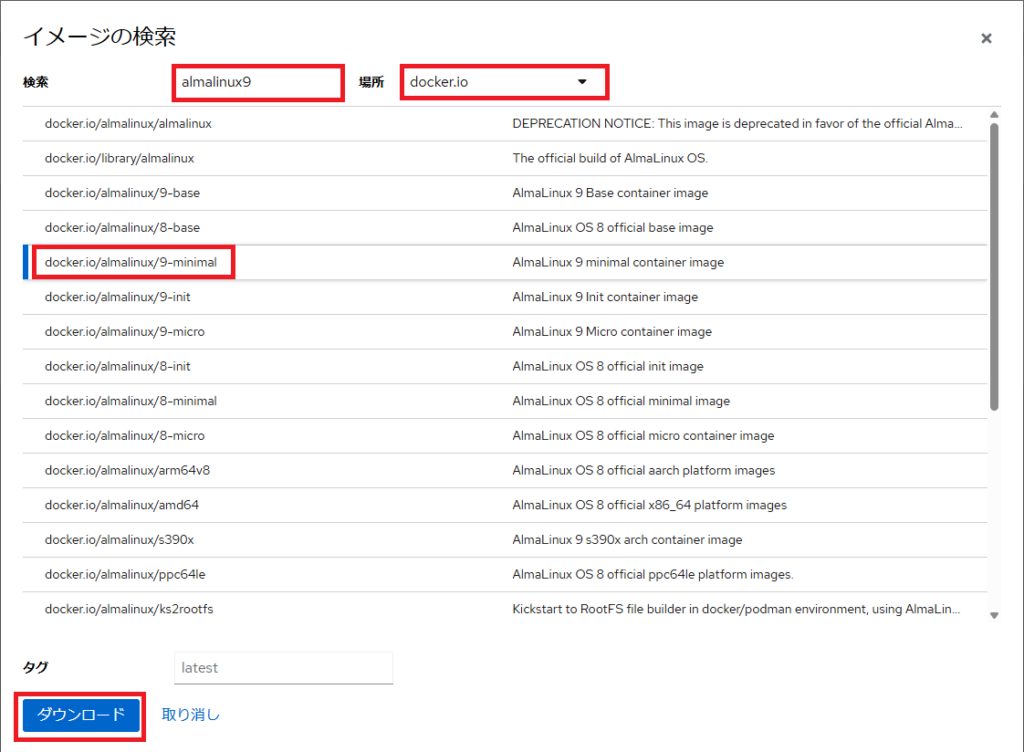
暫くすると
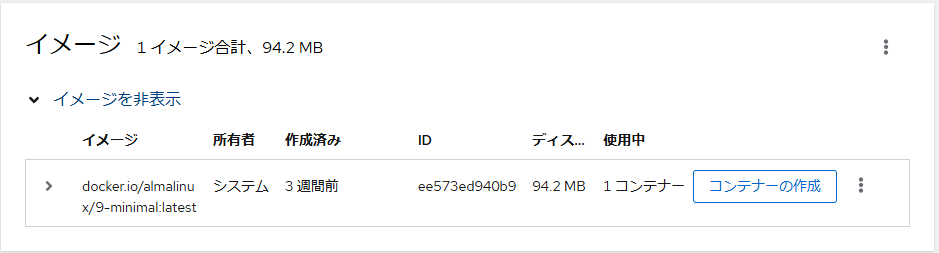
イメージは落とせたらしいので【コンテナーの作成】ボタンを押してコンテナを作る。
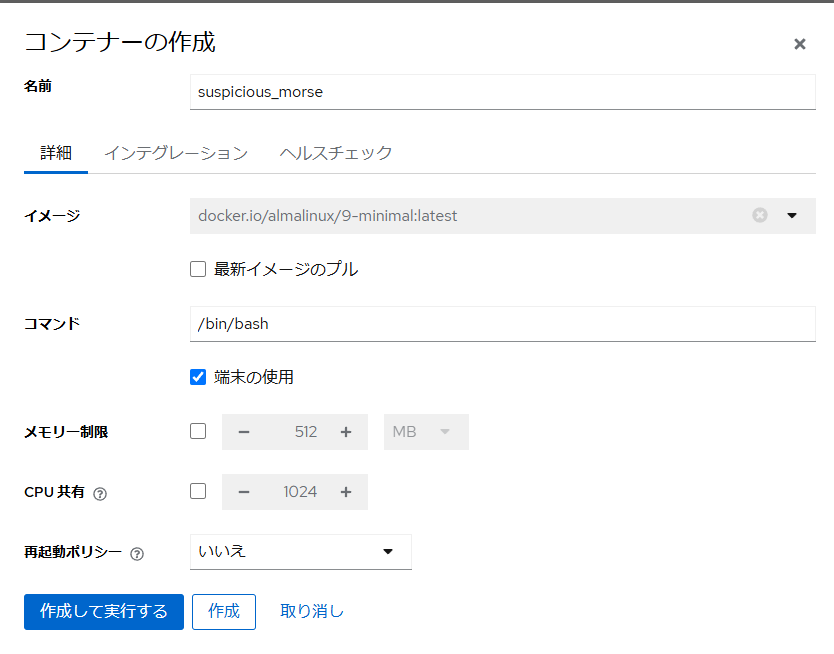
で動いてるっぽい。
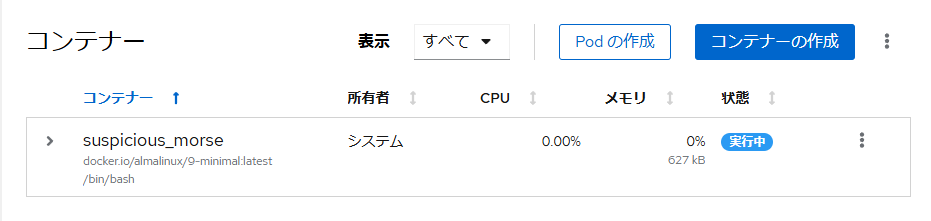
ここまではいいけど、どう繋げばいいんだろう?
と思ったら「コンソール」タグがあった。
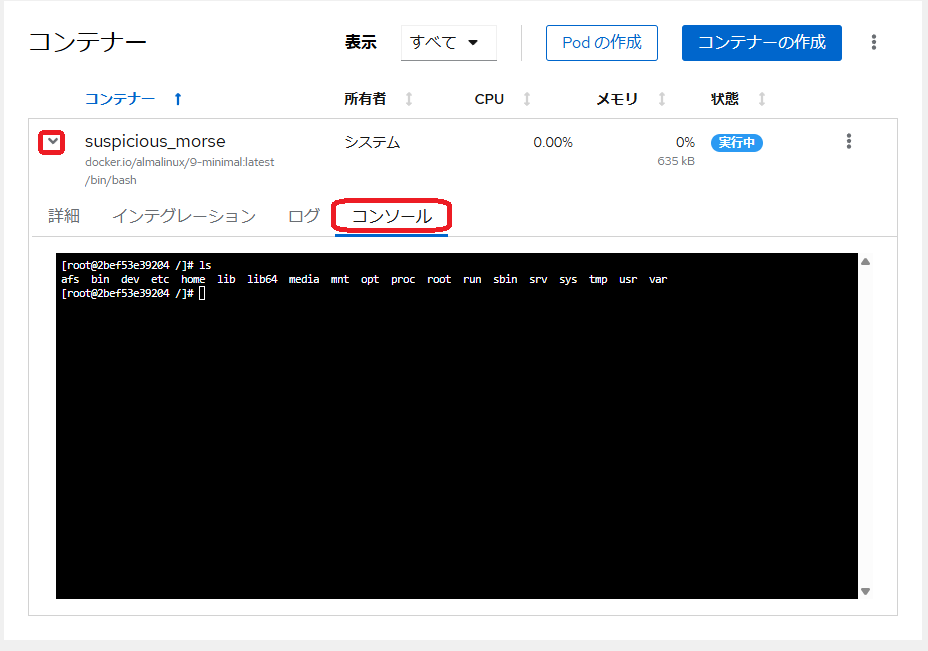
これで何かを付け足せば良いのだろうけど
dnfもtopも何も入ってないのでどうすればいいのかな?
インスト済みのコマンドならホストから実行できる。
# podman exec {コンテナ名} {コマンド} な感じで
# podman exec suspicious_morse ls -l
total 0
dr-xr-xr-x 2 root root 6 Oct 2 21:00 afs
lrwxrwxrwx 1 root root 7 Oct 2 21:00 bin -> usr/bin
drwxr-xr-x 5 root root 360 Mar 26 14:31 dev
drwxr-xr-x 1 root root 18 Mar 26 14:31 etc
drwxr-xr-x 2 root root 6 Oct 2 21:00 home
lrwxrwxrwx 1 root root 7 Oct 2 21:00 lib -> usr/lib
lrwxrwxrwx 1 root root 9 Oct 2 21:00 lib64 -> usr/lib64
drwxr-xr-x 2 root root 6 Oct 2 21:00 media
drwxr-xr-x 2 root root 6 Oct 2 21:00 mnt
drwxr-xr-x 2 root root 6 Oct 2 21:00 opt
dr-xr-xr-x 254 root root 0 Mar 26 14:31 proc
dr-xr-x--- 2 root root 91 Mar 7 07:52 root
drwxr-xr-x 1 root root 42 Mar 26 14:31 run
lrwxrwxrwx 1 root root 8 Oct 2 21:00 sbin -> usr/sbin
drwxr-xr-x 2 root root 6 Oct 2 21:00 srv
dr-xr-xr-x 13 root root 0 Mar 26 14:31 sys
drwxrwxrwt 2 root root 6 Oct 2 21:00 tmp
drwxr-xr-x 12 root root 144 Mar 7 07:52 usr
drwxr-xr-x 18 root root 235 Mar 7 07:52 varできるけどviすら無いから・・・
ただ rpm コマンドは入ってたので・・・
ホストからファイル転送すれば何とかなるかな???????
# podman cp {ホストファイルパス} {コンテナー名} : {コンテナーファイルパス}
外にファイル転送するには
# podman cp {コンテナー名} : {コンテナーファイルパス} {ホストファイルパス}
で使えるらしい。:の有無でホストとコンテナを区別してるっぽいので
# podman cp {コンテナー1} : {コンテナーファイルパス} {コンテナー2} : {コンテナーファイルパス}
もできそう。
首尾よく何かが出来上がったら、コンテナを停止してイメージを作ればいいのかな。
# podman stop {コンテナー名} か cockpitのpodmanのコンテナのメニューの【停止】
# podman commit {コンテナー名} {イメージ名} か コンテナのメニューの【コミット】
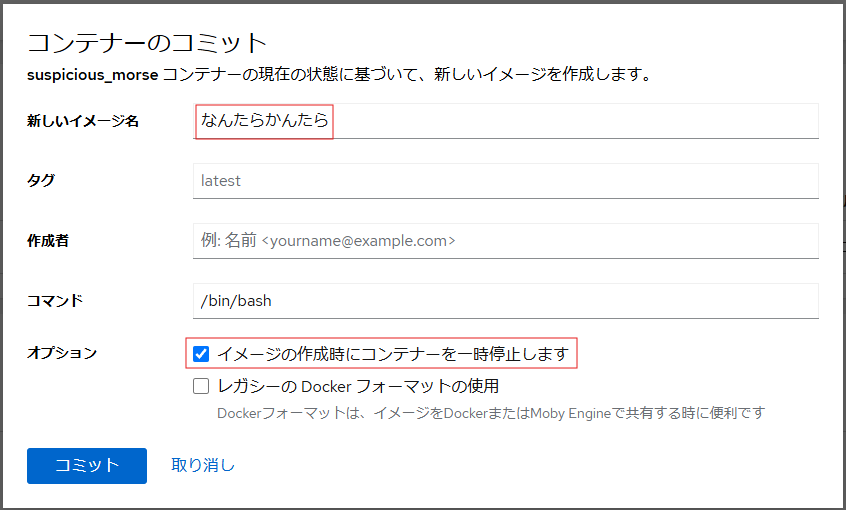
※「なんたらかんたら」はエラった