正規表現自体・・・
呪文
と呼ばれているので
下のテキストから正規表現の部分をパースしなさいとかは、難題
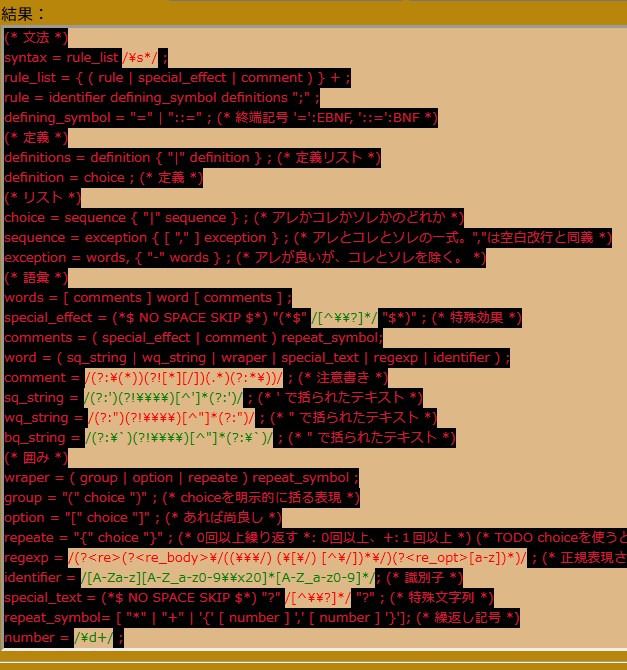
(* 文法 *)
syntax = rule_list /\s*/ ;
rule_list = { ( rule | special_effect | comment ) } + ;
rule = identifier defining_symbol definitions ";" ;
defining_symbol = "=" | "::=" ; (* 終端記号 '=':EBNF, '::=':BNF *)
(* 定義 *)
definitions = definition { "|" definition } ; (* 定義リスト *)
definition = choice ; (* 定義 *)
(* リスト *)
choice = sequence { "|" sequence } ; (* アレかコレかソレかのどれか *)
sequence = exception { [ "," ] exception } ; (* アレとコレとソレの一式。","は空白改行と同義 *)
exception = words, { "-" words } ; (* アレが良いが、コレとソレを除く。 *)
(* 語彙 *)
words = [ comments ] word [ comments ] ;
special_effect = (*$ NO SPACE SKIP $*) "(*$" /[^\\?]*/ "$*)" ; (* 特殊効果 *)
comments = ( special_effect | comment ) repeat_symbol;
word = ( sq_string | wq_string | wraper | special_text | regexp | identifier ) ;
comment = /(?:\(*))(?![*][/])(.*)(?:*\))/ ; (* 注意書き *)
sq_string = /(?:')(?!\\\\)[^']*(?:')/ ; (* ' で括られたテキスト *)
wq_string = /(?:")(?!\\\\)[^"]*(?:")/ ; (* " で括られたテキスト *)
bq_string = /(?:\`)(?!\\\\)[^"]*(?:\`)/ ; (* " で括られたテキスト *)
(* 囲み *)
wraper = ( group | option | repeate ) repeat_symbol ;
group = "(" choice ")" ; (* choiceを明示的に括る表現 *)
option = "[" choice "]" ; (* あれば尚良し *)
repeate = "{" choice "}" ; (* 0回以上繰り返す *: 0回以上、+:1回以上 *) (* TODO choiceを使うと exceptionで[undefined]が返る *)
regexp = /.+/([a-z]*) ;
identifier = /[A-Za-z][A-Z_a-z0-9\\x20]*[A-Z_a-z0-9]*/; (* 識別子 *)
special_text = (*$ NO SPACE SKIP $*) "?" /[^\\?]*/ "?" ; (* 特殊文字列 *)
repeat_symbol= [ "*" | "+" | '{' [ number ] ',' [ number ] '}']; (* 繰返し記号 *)
number = /\d+/ ;なので
regexp = /.+/([a-z]*) ;とか表記は誤魔化してたけど、
実際にはこれでパースするとテキストの終りの手前までヒットしてしまう。
とある記事で、エスケープ表現の文字を潜り抜けさせる方法が載ってた。
/@( (¥¥@)|([^@]) )+ @/ ※@は任意の文字
な感じで@のエスケープ表現の2文字と@以外の文字のいづれかを繰り返す表現をしていた。
これを真似て
/ ( ( \ / ( ( \ \ / ) | ( [ \ / ) | [^\ / ] ) * \ / ) ( [ a – z ] * ) ) /
/ \ / ( ( \ / ( ( \ \ \ / ) | ( \ [ \ / ) | ( \ ( \ / ) | ( [ ^ / ] ) ) * \ / ) ( [ a – z ] * ) ) / ※壊れてたので訂正 2025/5/6
※ps.2025/5/8 さっぱり通らなくなることはタマにある。が起きたので再訂正、正規表現デバッガもコピーボタンも2通りの書き方を出力するように変更(DevToolsを開きキャッシュクリア必須)。やはりコノPC何かが変なんだろうね?
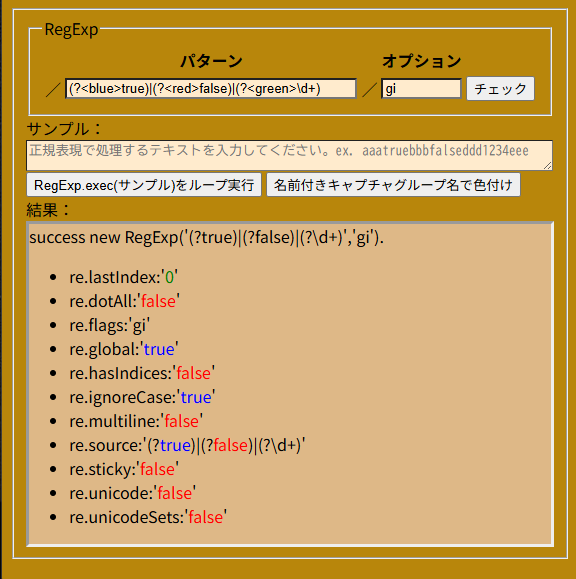
const re1 = new RegExp("(\\/((\\\\\\/)|(\\[\\/)|(\\(\\/)|([^/]))*\\/)([a-z]*)", "gim");
const re2 = /(\/((\\\/)|(\[\/)|(\(\/)|([^/]))*\/)([a-z]*)/gim;
※崩れた顔文字ではありません、読みにくいので空白を挿入しました。
を作って試してみた結果は
うまくいってるみたいだが、ヒットした正規表現の半分は顔文字にしか見えない。
しかも、長い。長すぎる~。
ps.2025/5/9
MDNでreplace系で使う置換する関数に渡るパラメータは
replace(/(/{2}.*$|\/\*\/?([^/]|[^*]\/|\r|\n)*\*\/)/, replacer);
👇
function replacer(match, p1, p2, /* …, */ pN, offset, string ) {
return replacement;
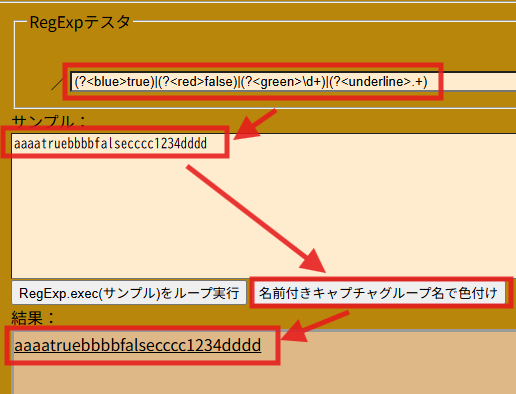
}で、「名前付きのキャプチャグループ」がある場合はgroupsが付加されて
replace(/(?<COMMENT>/{2}.*$|\/\*\/?([^/]|[^*]\/|\r|\n)*\*\/)/, replacer);
👇
function replacer(match, p1, p2, /* …, */ pN, offset, string, groups) {
return replacement;
}となっていたので、名無しの正規表現でもそれなりに色付けできるように上書き修正。
普通に
function replacer(match, p1, p2, … pN, offset, string, groups) {
// … pN 部分は全部pNに含まれる(だったらいいな的な
return replacement;
}みたいに…(残余引数)が使えたらいいけどね。
ps.2025/5/18
自身の表記が通らなかったので、
・・・|(\^\/\])|・・・を追記したら改行が通ってしまうので
[^/] を
[^/\r\n]に変更して
/(\/((\\\/)|(\^\/\])|(\[\/)|(\(\/)|([^/\r\n]))*\/)([dgimsuvy]*)/になったけど、BNFのテキストの正規表現内に
\r\nがあるとダメなのは当然なので
\\r\\nと表記しても通らない?
原因がよく解らないなぁと思ったら \が通らなくなっていた。
[^/\r\n]は、 / と¥とrとnを除外する意味と\r\nを除外する2つの意味を持ってしまっていた。
色々試してみた結果
x ([^/\r\n])
▲ ([^\r\n/]) \]っぽく処理されてダメだった
▲ ([^/]|[^\r\n]) 論理和だから条件が甘アマ
◎([^/\x0a\x0d]) 非推奨だけどらしい(微妙
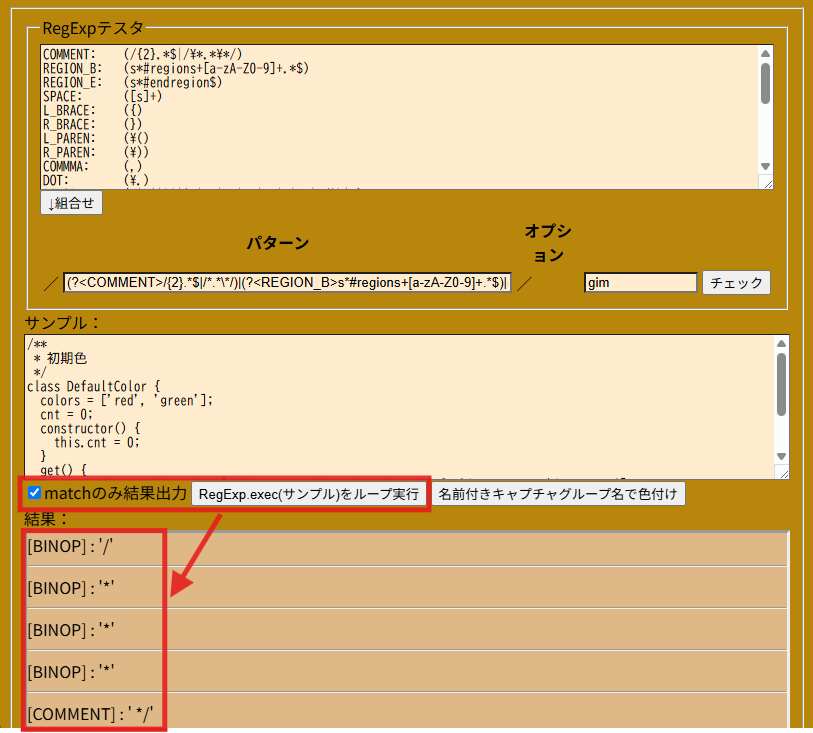
その後も「*/」のパターンが抜けてたり追記する度にエスケープさせるパターンが増える罠に遭遇し続けた結果がコレ
/(\/((\\\/)|(\^\/)|(\[\/)|(\(\/)|(\*\/)|([^/\x0a\x0d]))*\/)([dgimsuvy]*)/自身はちゃんと判定できるものの、「*/」は末端の「/」と判定しないから、
「/.*/aaaaaaa/」は、「/.*/aaaaaaa/」な正規表現と判定される訳で
正規表現はパーサコンビネーションで解消するしかないっぽい。
そうなるとまた際限がないので、
正規表現を
- / で始まり
- 特殊な文字「( ) { } [] . + *等」か その他の文字 の繰り返し
- / で終わる
の様な表現で括らないとダメな気がする。
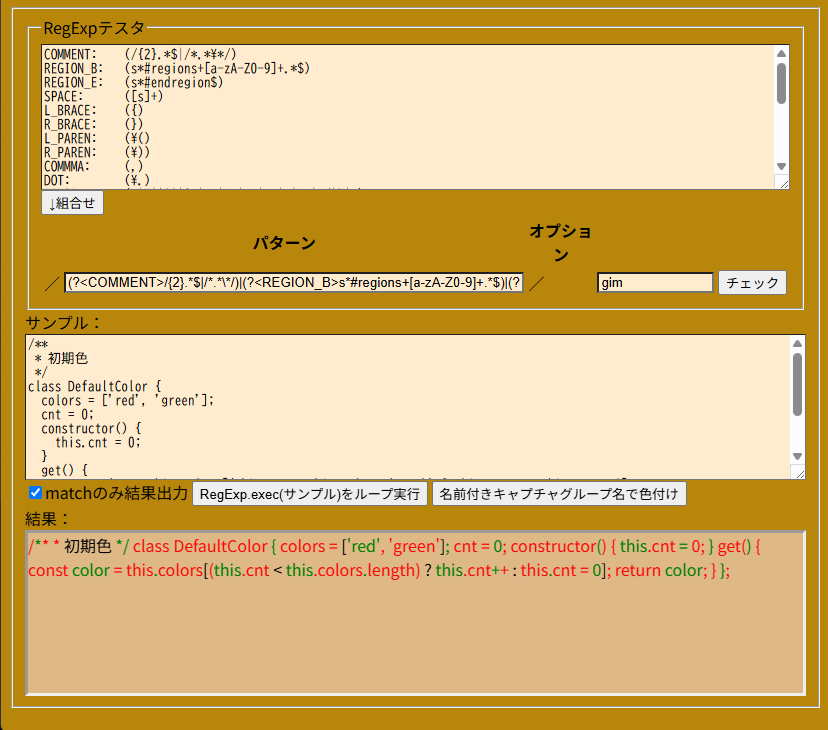
/(\/)((\\/)|([^/\x0a\x0d]))+(\/)([dgimsuvy]*)/のあたりで妥協して
EBNFで使うには文法上の利用方法を見直した方が良さそう。
でも、正規表現の文字クラスの中の文字クラスとかグループとか繰り返しとかを内包しないみたいなんで、[…]は/有無に関わらず通しても良さそう
/(\/)(((\\\/)|(\[.*?\])|([^/\r\n\s]))+)?(\/)([dgimsuvy]*)/gmuyで、何とかならないかな?
2か所で使っている最短マッチング(x?y)が微妙で、chromeでもnode.jsでも
1つ目はグループを入れて見やすくしたり手を入れると、通常の最長マッチングになり
◎ (\[.*?\])
× ((\[.*)?(\])) xというか通常の最長マッチングになる場合がある文末に近いコメントの中の ] までマッチングしてしまうが、
/(\\/)((\\\\/)|((\[.*)?(\]))|([^/]))+(\\/)(dgimsuvy*)/ ; (* 正規表現されたテキスト + /.+/ "/" + { /[dgimsuvy]/ } *)2つ目は(…)?(\/)とグループにして入れても支障は無い。
どうやら(…)で括ると \[ が [ みたいに階層無しに思え最長マッチング(つまり通常のマッチング)してる気もするが([.*?])単体では最短マッチングするので、最短マッチングを階層の上と下で使う分には問題ないけど、その両方の?の両辺をグループにしてしまうとマッチングの位置(position)をうっかり共有してしまってる(VMの変数のネーミングが被ってるかVMのコンパイラには同じに見えている)気がする。
それに、VScodeのjsファイルのエディタで(\\\/)部分がダメで(\\\\/)で通る様にしたのが上の正規表現だったりするので、雑な正規表現は微妙な動きをするのは仕方が無いのかもしれない。