XmlDocumentの構成とかjavascriptでの読み方とか
xmlData.getElementsByTagName("要素名")[0]
とか
xmlData.querySelect(セレクター)
とかな感じで検索する記事はあるけど、ザーット表示する記事はなかった。
ま、ブラウザで表示すればいいからね。
でも自作のTreeViewもどきで作った。
APIはまだ無いので自力でTreeViewにHTMLobjectを書き込まないといけない。
<div class="tree_view">
<!-- level 1 -->
<div class="element open"><tag-name attr-name1="xxxxxx" attr-name2="xxxxxx" >
<div class="contener">
<!-- level 2 -->
<div class="context">テキスト1</div>
<div class="context">テキスト2</div>
<div class="context">テキスト3</div>
<div class="context">テキスト4</div>
<div><tag-name2/></div>
</div>
<div class="element-end"></tag-name1></div>
</div>
<!-- level 1 -->な感じでHTMLを作ると
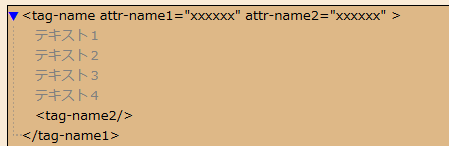
な雰囲気で表示するところまで地味にcssを書いて
body {
background-color: antiquewhite;
}
div.tree_view {
background-color: burlywood;
font-family: 'メイリオ', 'Meiryo', 'MS ゴシック', 'Hiragino Kaku Gothic ProN', 'ヒラギノ角ゴ ProN W3', sans-serif;
font-size: 10pt;
height: 100%; width: calc(100% - 20px);
margin: 10px; border: solid black 1px; padding-left: 1em;
}
div.marker {
vertical-align: top;
display: inline-block;
width: 1em;
border: solid blue 1px;
}
div.element {
margin-right: 6px;
}
(省略)点線も描いて
<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 16 16" width="16" height="16">
<path d="M 0,0,0,9,14,9" fill="none" stroke="gray" stroke-dasharray="2" />
</svg>後は、XMLファイルを読んで終了。
・・・
/**
* ファイルボタンのファイル選択イベント
* @param {*} event
*/
onSelectedFile = (event) => {
// A file selection event occurred.
console.log(`file selection event occurred. '${Array.from(event.target.files).map((a) => a.name).join(', ')}'`);
// Get a file object.
const fileObjects = event.target.files;
// 過去歴をクリア
this.xmlDocuments = [];
clearnHtmlObjectTextContent(this.outputHtmlObject);
// Load file
this.loadFiles(fileObjects, this.readXml, this.outputHtmlObject);
};
/**
* load fileObject
* @param {FileList} fileObjects
* @param {*} contextReader
* @param {*} outputHtmlObject
*/
loadFiles = (fileObjects, contextReader, outputHtmlObject) => {
Array.from(fileObjects).map((fileObject) => {
const fr = new FileReader();
fr.addEventListener('load', (event) => {
// ファイルのテキストを取得
const xmlContext = event.target.result;
contextReader(xmlContext, outputHtmlObject);
});
fr.readAsText(fileObject);
});
}
(省略)
// setup
window.addEventListener("load", () => {
const xmlView = new TreeView(document.querySelector(`#file`), document.querySelector(`.tree_view`));
// tree_view の▼と▶の切替
window.addEventListener("click", (event) => {
if (Array.from(event.target.classList).some((e) => e === 'element')) {
const target = event.target; target.classList.toggle('open');
const chLst = Array.from(target.childNodes).filter((ch) => {
return ((!ch.classList) ? false : Array.from(ch.classList).some((cl) => cl === 'contener'));
});
(chLst).forEach(ch => ch.classList.toggle('hidden'));
};
});
});のハズだったけど、
new DOMParser().parseFromString(xmlText, ‘application/xml’)で得られる
XmlDocumentのMDNの説明はDocument→Nodeクラスの派生型です。(説明終わり
仕方なく汎用XML解析ルーチンaddTreeListByXmlを作ることに
tagNameが無い場合はnodeNameが「#TEXT」なんで、テキストコンテキストノードっぽいのでtextContentのみ設定とかXMLを読んだ結果を見ながら行き当たりばったりで書いた。
配下のオブジェクトはchildListかなと思ったけど、childNodesの方だった。
属性はgetAttributeNames()で属性名を取得してgetAttribute(属性名)で値が判る。
そんな雰囲気なので作ってみた感想は目新しいメソッドも特に無いから
XmlDocumentクラスはDocument→Nodeクラスの派生です。
という説明で充分かもしれない。
TreeViewのAPIもWindowsのみたいに細かく作るよりJSON形式のデータを渡すとそれっぽく表示する程度で充分かな
ps.2025/4/22:カスタムエレメント化した。
<body>
<label for="fileXmlDom">parseFromString(fileText)</label><input type="file" id="fileXmlDom" value="XmlDom"><br />
<label for="fileXmlText">replaceAll(/x/g,xmlReplacer)</label><input type="file" id="fileXmlText" value="XmlText">
<tree-view id="tree_view_sample" width="500px" height="600px" tabindex="1" resize="both" overflow="auto">
</tree-view>
</body>String.replaceAll({正規表現パターン、置換処理})の結果をinnerHTMLで展開
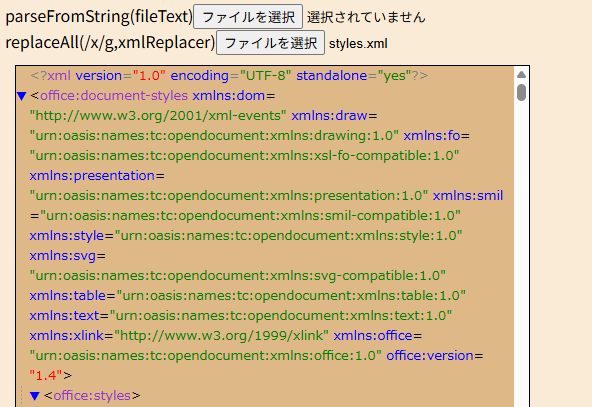
XMLParserのparseFromString({XMLテキスト})の結果(DOMツリー)を展開
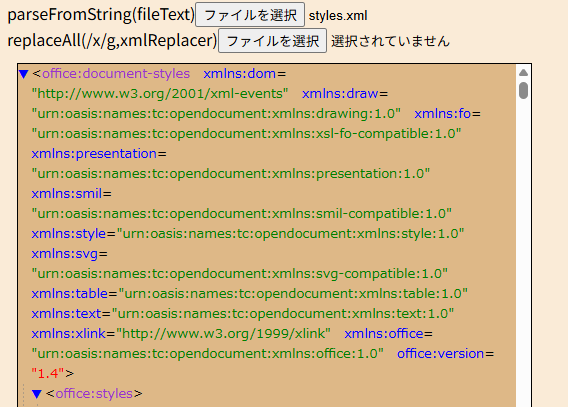
いづれも長いコード書かないとツリービュー化できないでいる。
ReplaceAllの方はHTMLも読めなくもないが、末端に正しく(?)「/>」が入っていないと南京玉簾になる。
とりあえず、オブジェクトだったら配下のオブジェクトを調べる方法を画一化(childListとか)してみたい。