FROM almalinux:latest
RUN dnf -y update
RUN dnf -y install mariadb mariadb-server
COPY carset.cnf /etc/my.cnf.d/charset.cnf
RUN systemctl enable mariadb
RUN dnf clean all;
# コンテナでport指定が必須なのでEXPOSEは注意書き程度の意味
EXPOSE 3306
CMD [ "/sbin/init" ]
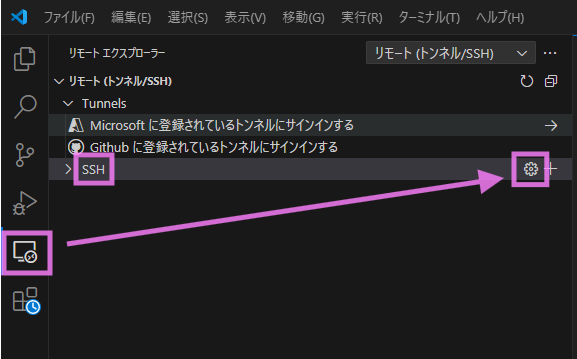
コンテナ内でsystemdを実行する方法 の記事で、podman run のマニュアルが抜粋されてた。
# man podman run
・・・
--systemd=true | false | always
Run container in systemd mode. The default is true.
• true enables systemd mode only when the command executed inside the container is systemd, /usr/sbin/init, /sbin/init or /usr/local/sbin/init.
• false disables systemd mode.
• always enforces the systemd mode to be enabled.
Running the container in systemd mode causes the following changes:
• Podman mounts tmpfs file systems on the following directories
• /run
• /run/lock
• /tmp
• /sys/fs/cgroup/systemd (on a cgroup v1 system)
• /var/lib/journal
• Podman sets the default stop signal to SIGRTMIN+3.
• Podman sets container_uuid environment variable in the container to the first 32 characters of the container ID.
• Podman does not mount virtual consoles (/dev/tty\d+) when running with --privileged.
• On cgroup v2, /sys/fs/cgroup is mounted writeable.
This allows systemd to run in a confined container without any modifications.
Note that on SELinux systems, systemd attempts to write to the cgroup file system. Containers writing to the cgroup file system are denied by default. The container_manage_cgroup boolean must
be enabled for this to be allowed on an SELinux separated system.
setsebool -P container_manage_cgroup true
・・・
podman run –systemd=trueオプションがデフォなので、/sbin/initを指定すれば動く(ハズが動かない
[FAILED] Failed to start MariaDB 10.5 database server.
See 'systemctl status mariadb.service' for details.
不穏な雰囲気が・・・
# podman exec almalinux9_mariadb_contener systemctl status mariadb.service
# mariadb.service - MariaDB 10.5 database server
Loaded: loaded (/usr/lib/systemd/system/mariadb.service; enabled; preset: disabled)
Active: failed (Result: exit-code) since Wed 2025-04-02 16:46:32 UTC; 2min 7s ago
Docs: man:mariadbd(8)
https://mariadb.com/kb/en/library/systemd/
Process: 23 ExecStartPre=/usr/libexec/mariadb-check-socket (code=exited, status=0/SUCCESS)
Process: 46 ExecStartPre=/usr/libexec/mariadb-prepare-db-dir mariadb.service (code=exited, status=1/FAILURE)
CPU: 349ms
Apr 02 16:46:32 90b2f5aeb4b0 mariadb-prepare-db-dir[112]: chown: changing ownership of '/var/lib/mysql': Operation not permitted
Apr 02 16:46:32 90b2f5aeb4b0 mariadb-prepare-db-dir[87]: Cannot change ownership of the database directories to the 'mysql'
Apr 02 16:46:32 90b2f5aeb4b0 mariadb-prepare-db-dir[87]: user. Check that you have the necessary permissions and try again.
Apr 02 16:46:32 90b2f5aeb4b0 mariadb-prepare-db-dir[46]: Initialization of MariaDB database failed.
Apr 02 16:46:32 90b2f5aeb4b0 mariadb-prepare-db-dir[46]: Perhaps /etc/my.cnf is misconfigured or there is some problem with permissions of /var/lib/mysql.
Apr 02 16:46:32 90b2f5aeb4b0 mariadb-prepare-db-dir[46]: Initialization of MariaDB database was not finished successfully.
Apr 02 16:46:32 90b2f5aeb4b0 mariadb-prepare-db-dir[46]: Files created so far will be removed.
Apr 02 16:46:32 90b2f5aeb4b0 systemd[1]: mariadb.service: Control process exited, code=exited, status=1/FAILURE
Apr 02 16:46:32 90b2f5aeb4b0 systemd[1]: mariadb.service: Failed with result 'exit-code'.
Apr 02 16:46:32 90b2f5aeb4b0 systemd[1]: Failed to start MariaDB 10.5 database server.
# podman exec almalinux9_mariadb_contener chown -R mysql:mysql /var/lib/mysql
# podman exec almalinux9_mariadb_contener systemctl start mariadb
# podman exec almalinux9_mariadb_contener systemctl status mariadb.service
● mariadb.service - MariaDB 10.5 database server
Loaded: loaded (/usr/lib/systemd/system/mariadb.service; enabled; preset: disabled)
Active: active (running) since Wed 2025-04-02 16:51:09 UTC; 18s ago
Docs: man:mariadbd(8)
https://mariadb.com/kb/en/library/systemd/
Process: 120 ExecStartPre=/usr/libexec/mariadb-check-socket (code=exited, status=0/SUCCESS)
Process: 142 ExecStartPre=/usr/libexec/mariadb-prepare-db-dir mariadb.service (code=exited, status=0/SUCCESS)
Process: 251 ExecStartPost=/usr/libexec/mariadb-check-upgrade (code=exited, status=0/SUCCESS)
Main PID: 230 (mariadbd)
Status: "Taking your SQL requests now..."
Tasks: 20 (limit: 1638)
Memory: 75.5M
CPU: 1.081s
CGroup: /system.slice/mariadb.service
└─230 /usr/libexec/mariadbd --basedir=/usr
Apr 02 16:51:08 90b2f5aeb4b0 mariadb-prepare-db-dir[181]: The second is mysql@localhost, it has no password either, but
Apr 02 16:51:08 90b2f5aeb4b0 mariadb-prepare-db-dir[181]: you need to be the system 'mysql' user to connect.
Apr 02 16:51:08 90b2f5aeb4b0 mariadb-prepare-db-dir[181]: After connecting you can set the password, if you would need to be
Apr 02 16:51:08 90b2f5aeb4b0 mariadb-prepare-db-dir[181]: able to connect as any of these users with a password and without sudo
Apr 02 16:51:08 90b2f5aeb4b0 mariadb-prepare-db-dir[181]: See the MariaDB Knowledgebase at https://mariadb.com/kb
Apr 02 16:51:08 90b2f5aeb4b0 mariadb-prepare-db-dir[181]: Please report any problems at https://mariadb.org/jira
Apr 02 16:51:08 90b2f5aeb4b0 mariadb-prepare-db-dir[181]: The latest information about MariaDB is available at https://mariadb.org/.
Apr 02 16:51:08 90b2f5aeb4b0 mariadb-prepare-db-dir[181]: Consider joining MariaDB's strong and vibrant community:
Apr 02 16:51:08 90b2f5aeb4b0 mariadb-prepare-db-dir[181]: https://mariadb.org/get-involved/
Apr 02 16:51:09 90b2f5aeb4b0 systemd[1]: Started MariaDB 10.5 database server.
# podman exec -it almalinux9_mariadb_contener mariadb
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 5
Server version: 10.5.27-MariaDB MariaDB Server
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MariaDB [(none)]> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
+--------------------+
3 rows in set (0.001 sec)
MariaDB [(none)]> show variables like 'port';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| port | 3306 |
+---------------+-------+
1 row in set (0.003 sec)
MariaDB [(none)]> exit
Bye
#
なので多分OK。
でも【停止】させた表示が少し気になるので コンテナに-it は付けない方がいいかも。
Unmounting /etc/hostname...
Unmounting /etc/hosts...
Unmounting /etc/resolv.conf...
Unmounting /run/.containerenv...
Unmounting /run/lock...
Unmounting /run/secrets...
Unmounting Temporary Directory /tmp...
Unmounting /var/lib/mysql...
Unmounting var-log-journal.mount...
[FAILED] Failed unmounting /etc/hostname.
[FAILED] Failed unmounting /etc/hosts.
[FAILED] Failed unmounting /etc/resolv.conf.
[FAILED] Failed unmounting /run/.containerenv.
[FAILED] Failed unmounting /run/lock.
[FAILED] Failed unmounting /run/secrets.
[FAILED] Failed unmounting Temporary Directory /tmp.
[FAILED] Failed unmounting /var/lib/mysql.
[FAILED] Failed unmounting var-log-journal.mount.
[ OK ] Stopped target Swaps.
[ OK ] Reached target System Shutdown.
[ OK ] Reached target Unmount All Filesystems.
[ OK ] Reached target Late Shutdown Services.
Starting System Halt...
Sending SIGTERM to remaining processes...
Sending SIGKILL to remaining processes...
All filesystems, swaps, loop devices, MD devices and DM devices detached.
Halting system.
Exiting container.
disconnected
# podman run -a \
--name almalinux9a \
-it \
--rm \
docker.io/almalinux/9-minimal
✔ docker.io/library/almalinux9a:latest
Trying to pull docker.io/library/almalinux9a:latest...
Error: initializing source docker://almalinux9a:latest: reading manifest latest in docker.io/library/almalinux9a: requested access to the resource is denied